Szenarienbildung und Bewertung
Das Legal-AI-Lab ist eine KI-Sandbox, um KI-Use-Cases im Wege des Rapid Prototyping zu verproben. Der Schwerpunkt liegt dabei in der Verzahnung businessbezogener, technischer und regulatorischer Aspekte, die sich wechselseitig beeinflussen. Zur KI-basierten Bewertung verschiedener Szenarien nutzt das Legal-AI-Lab auch einen Digital Twin des Skripts.
KI-Nutzung muss häufig mit fachlichen Prozessen in Einklang gebracht werden. Dabei sind Zuständigkeiten, Budgets und Rechenschaftspflichten zu berücksichtigen. Gleiches gilt für das realistische Abschätzen erforderlicher Ressourcen. All dies unter Berücksichtigung einer hohen wirtschaftlichen und technischen Dynamik.
Um die Vielzahl von Herausforderungen entlang von spezifischen Abläufen identifizieren, strukturieren und lösen zu können, empfiehlt sich im Bereich der KI die Methode des Rapid Prototyping.
KI-Recht und Rapid Prototyping
Mit Rapit Prototyping können KI-Szenarien verprobt und verglichen werden. Dies ermöglicht nicht nur ein besseres Verständnis der zu lösenden Herausforderungen bei KI-basierten
- HR-Prozessen
- Sales-Prozessen
- Knowledge-Managment-Prozessen
- Kommunikations-Prozessen oder
- Content-Erstellungs-Prozessen
Rapid Prototyping hilft auch zu verstehen, wie KI in unterschiedlichen Varianten effektiv, effizient und rechtskonform eingesetzt werden kann. So können für ein und den gleichen Lösungsansatz unterschiedliche GPAI-Modelle infrage kommen, die unterschiedliche (rechtliche) Vor- und Nachteile besitzen. Mittels Rapid Prototyping werden mehrere Szenarien mit unterschiedlichem Chancen-/Risiko-Verhältnis systematisch verglichen:
- Bei Nutzung unterschiedlich spezialisierter GPAI-Modelle
- der Verwendung von Open Source Komponenten oder
- bei remote-AI-Services, bei denen die Nutzer eigene API-Keys verwenden
Das dem Skript zugrundeliegende Legal-AI-Lab beruht auf einem für Legal-Themen spezialisierten Python-Framework. Es ermöglicht, individuelle Unternehmens-Prozesse in kürzester Zeit aufzusetzen, zu simulieren und im Hinblick auf den Einsatz von KI (rechtlich) zu durchleuchten. Dabei kann die KI in der Plattform auf Gesetzestexte und Checklisten zurückgreifen, die via SQL verbunden sind: Zum EU AI Act, der DSGVO oder dem BGB. Integriert ist auch der gesamte Inhalt des Skripts „Grundwissen KI-Recht“. Die Rechtsquellen werden in einem mehrstufigen Prozess mittels KI auf die unterschiedlichen Szenarien übertragen.
Kurzum, das Legal-AI-Lab nutzt seinerseits KI, um rechtliche Herausforderungen eines Prototypen zu beleuchten. Entscheiden muss aber am Ende immer der Mensch.
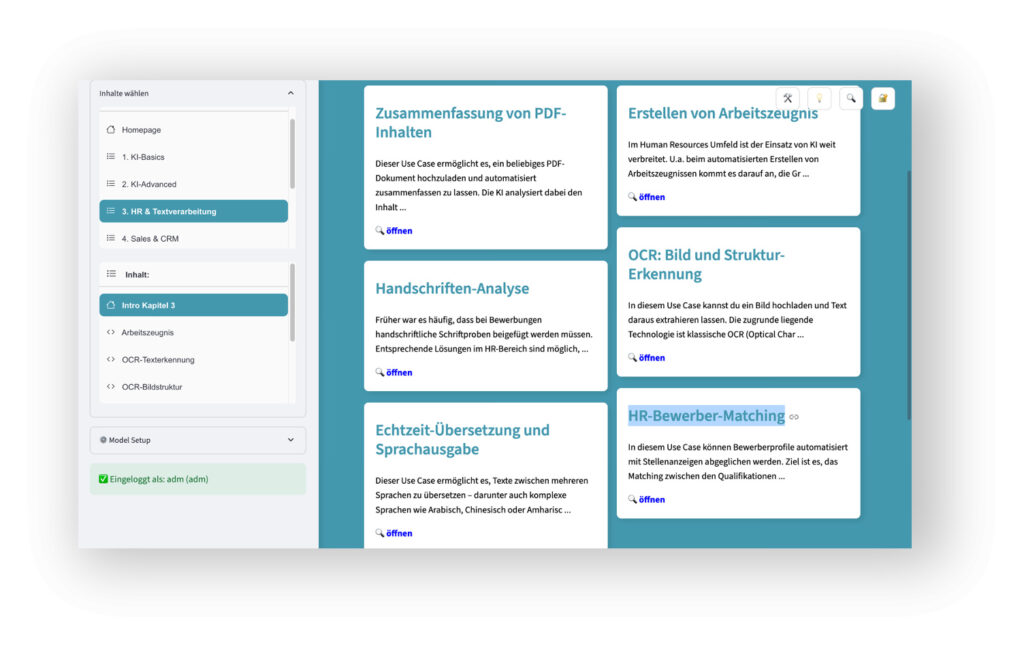
Kontextbezogene Use Cases
Das Legal-AI-Lab wurde auf Basis von Python, Streamlit und Ollama erstellt. Die Infrastruktur ist umfassend VPS-fähig (Virtual Private Server). Eingabe-Daten bleiben daher immer lokal. Die Sandbox dient dabei primär der lokalen Nutzung im Rahmen von Schulungen und Trainings, um Zusammenhänge rechtlicher und technischer Aspekte kontextbezogen zu verdeutlichen, z.B.:
- Was ist eine „Halluzination“ in Abgrenzung zum „Münchhausen-Effekt“ (u.a. wichtig für Fragen der Haftung)?
- Wie funktioniert Emotionserkennung und wie kann sie manipuliert werden (u.a. wichtig für Verbotene KI und die Risiko-Klassen)?
- Was unterscheidet KI-Systeme und GPAI-Modelle bei Services wie „gpt-4o“ oder „gpt-search-preview“ (u.a. wichtig für Rollen und Pflichten)?
Das Verständnis entsprechender Aspekte ist in mehrfacher Hinsicht praxisrelevant! Dazu ein Beispiel aus der Finanzwirtschaft:
- Der Unterschied einer regelbasierten Kreditentscheidung (diese fällt nicht unter den EU AI Act) und einer KI-basierten Kreditentscheidung (diese ist Hochrisiko-KI i.S.d. EU AI Acts) kann auf wenigen Zeilen Quellcode beruhen.
- Die Nutzeroberfläche bleibt dabei gleichwohl nahezu identisch. Mitunter ist auch zu differenzieren, ob und wie weit die Kreditentscheidung von einer KI faktisch getroffen wird oder die KI nur das Ergebnis formuliert. Nicht jede KI-Nutzung fällt bei einer Kreditvergabe unter die Hochrisiko-Vorschriften.
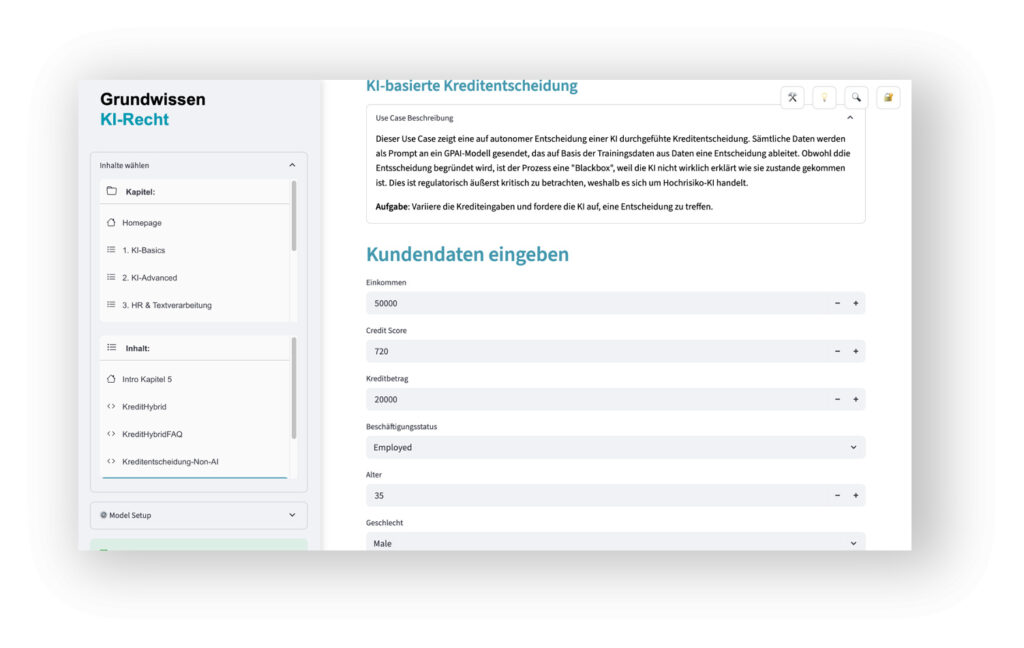
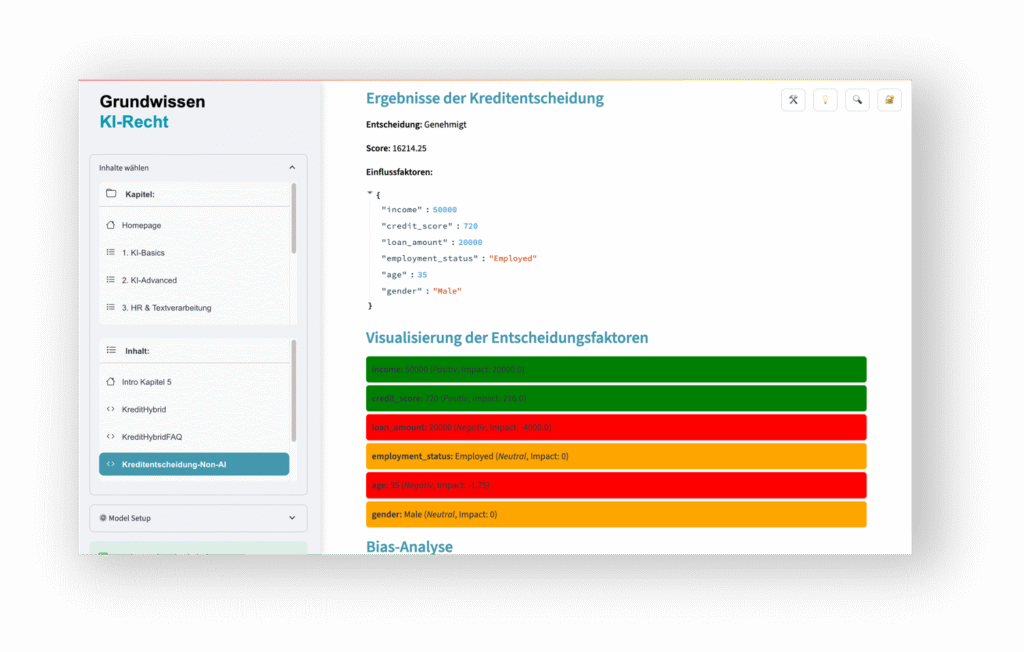
Der digitale KI-Twin
Um relevante Use Cases kontextbezogen erklären zu können, enthält das Legal-AI-Lab einen digitalen Zwilling des Skripts. Dies ermöglicht das direkte Vernetzen von operativen KI-Beispielen mit den rechtlichen Inhalten des Skripts.
Im Legal-AI-Lab integriert sind u.a.:
- Ein KI-Chat, der Inhalte des Skripts mit unterschiedlichen GPAI-Modellen erklärt (z.B. rechtliche Fachbegriffe, Beispiele oder Inhalte von Randnummern).
- Eine Datenbank-Anbindung mit Gesetzestexten zur kontextbezogenen Anzeige von Artikeln, Paragrafen, Erwägungsgründen und Anhängen.
- Das autonome Erstellen KI-generierter Quizfragen zu allen Inhalten des Skripts. Die KI bewertet und benotet die Antworten nach unterschiedlichen Vorgaben – und demonstriert so zugleich einen Hochrisiko-Use-Case i.S.v. Art. 6 (2) EU AI Act i.V.m. Anhang III Nr. 3 b).
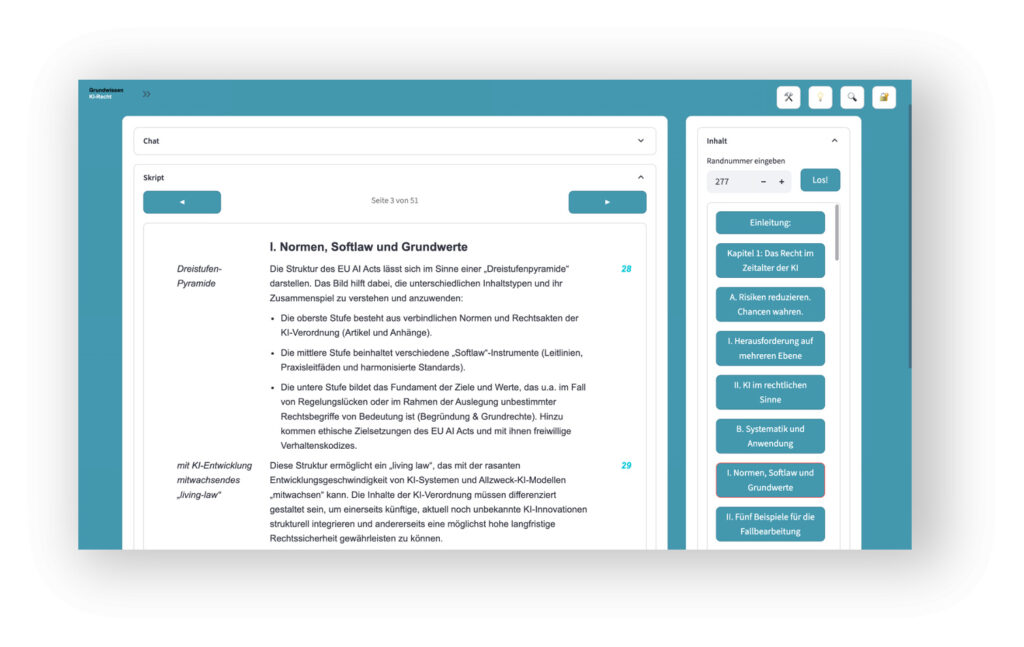
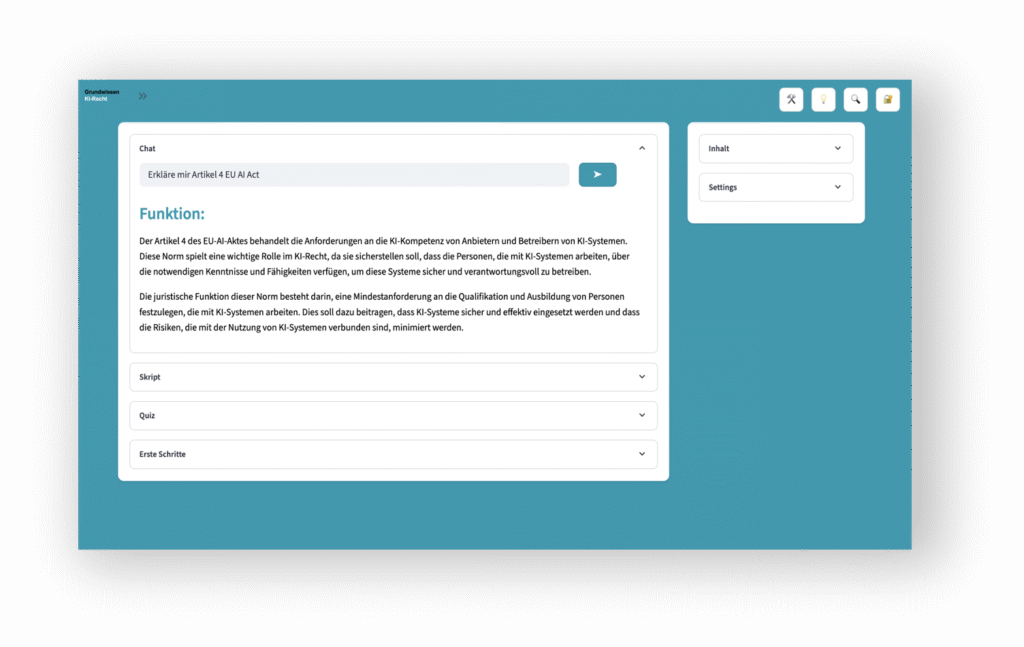
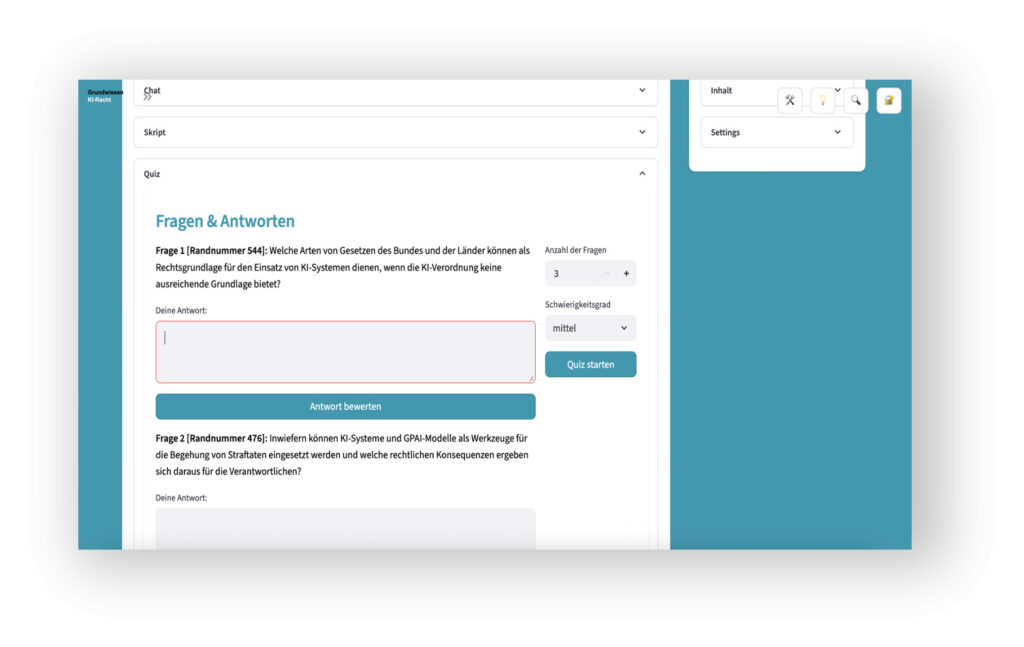
Zusammenhänge verstehen
Auf Basis dieser und weiterer Funktionen werden abstrakte rechtliche Fragestellungen im technisch-organisatorischem Kontext anhand von Szenarien erlebbar und vergleichbar. Exemplarisch genannt sei die zuvor erwähnte Bewertung juristischer Prüfungen durch KI:
- Je nachdem, welches GPAI-Modell angebunden ist, können Bewertungen ein und der gleichen Prüfung aufgrund unterschiedlicher Trainingsdaten stark unterschiedlich ausfallen.
- Je nach Konfiguration der Lösungsvorlagen kann die Vergabe von Noten und deren Begründung willkürlich und wenig nachvollziehbar erscheinen. Auch die potenzielle Beeinflussung von Co-Prüfern durch KI wird erlebbar.
- Je nach RAG-Variante (z.B. der dabei verwendeten Vektorisierung sowie Chunk- und Kontext-Größe) können rechtliche Bewertungen mitunter auch sogar völlig falsch sein, weil die zu prüfenden Texte von der KI zufällig „zerrissen“ und ihre Inhalte damit verfälscht werden.
Die vorherigen Beispiele dienen u.a.:
- Der Abschätzung von Herausforderungen bei der Umsetzung von Pflichten für Hochrisiko-KI entsprechend der Art. 8 ff. EU AI Act. Dies entlang des gesamten Life-Cycles, beginnend bei der Konzeption bis hin zum Monitoring und der Bestimmung und Durchführung von Schulungen.
- Der Evaluation von qualitätsrelevanten Faktoren, die eher auf Seiten des umgebenden KI-Systems oder des im konkreten Einzelfall verwendeten GPAI-Modells liegen.
- Der Darstellung von Einflüssen, die Outputs in den Bereich „rechtlicher Halluzinationen“ abdriften lassen. Gleiches gilt für den „Münchhausen-Effekt“: Letzterer beschreibt den Fall, dass sich eine KI nicht nur zufällig irrt (dann Halluzination), sondern die eigene falsche Einschätzung nachhaltig vehement verteidigt.
- Dabei kann es zu regelrechten „KI-Lügen“ kommen. Zudem könnte eine KI beginnen, in autoritärer Form, unwahre Behauptungen zu wiederholen oder die Kompetenz derjenigen Nutzer gewieft infrage zu stellen, welche die menschliche Aufsicht durchführen und die Outputs faktisch und rechtlich kritisch hinterfragen.
Typische Fehlfunktionen erleben
Wichtig ist insbesondere, die oft schwer erkennbaren Fälle rechtlicher Fehlfunktionen von KI zu kennen. Typische Beispiele sind:
- Das Erfinden von nicht existierenden rechtlichen Normen, Rechtsfällen oder Gerichtsurteilen aller Art (Halluzinationen).
- Die nachhaltig rechtlich falsche Beurteilung von Sachverhalten trotz wiederholter Korrekturhinweise auf Nutzerseite (Münchhausen-Phänomen).
- Die Behauptung, dass rechtlich relevante Originaltexte von der KI gelesen und berücksichtigt wurden, dies aber tatsächlich gar nicht der Fall ist (Münchhausen-Phänomen).
Dies sind Faktoren, die sich auf die Art und Weise auswirken, wie eine (juristische) Hochrisiko-KI umgesetzt und dokumentiert werden sollte, um allgemeinen und besonderen Sorgfaltspflichten gerecht zu werden. Die diesbezüglichen Aspekte sind auf nahezu alle Use Cases übertragbar, bei denen generative KI eingesetzt wird. Egal welcher Branche oder Risikoklasse.
Intensionen automatisch erkennen
Ein wichtiger algorythmischer Use Case des Legal-AI-Lab (speziell bei der Verwendung des KI-Chats) ist die automatische Erkennung unterschiedlicher Intensionen von Nutzereingaben bzw. Prompts. Die potenzielle Vielzahl möglicher rechtlicher Fragen kann es erfordern, dass unterschiedliche KI-Techniken zur Generierung rechtlicher Antworten genutzt werden müssen:
- Mal überwiegend regelbasiert
- mal durch semantische Auswertung auf Basis neuronaler Netze
Dies gilt u.a. für Fragen, die verschiedene Rechtsbereiche betreffen, z.B. das Zivilrecht, Strafrecht oder KI-Recht. Die jeweils einschlägigen Gesetze sollten bei der Chat-Eingabe erkannt und den Prompt automatisch zu unterschiedlichen rechtlichen Expertensystemen weiterleiten.
Das heißt:
- Fragen, die rechtliche Normen oder Definitionen betreffen, sollten nicht nur aus einem RAG-System heraus, sondern stets auch auf Basis einer Gesetzes-Datenbank beantwortet werden (z.B. „was bedeutet Inverkehrbringen i.S.d. KI-VO“?).
- Prompts zu Internet-Suchen, sollten automatisch spezifische Such-Services aktivieren (z.B. DuckDuckGo oder gpt-4o-search-preview). Diese sind als API-Service hoch spezialisierte KI-Systeme. Sie können rechtlich anders zu bewerten sein wie GPAI-Modelle.
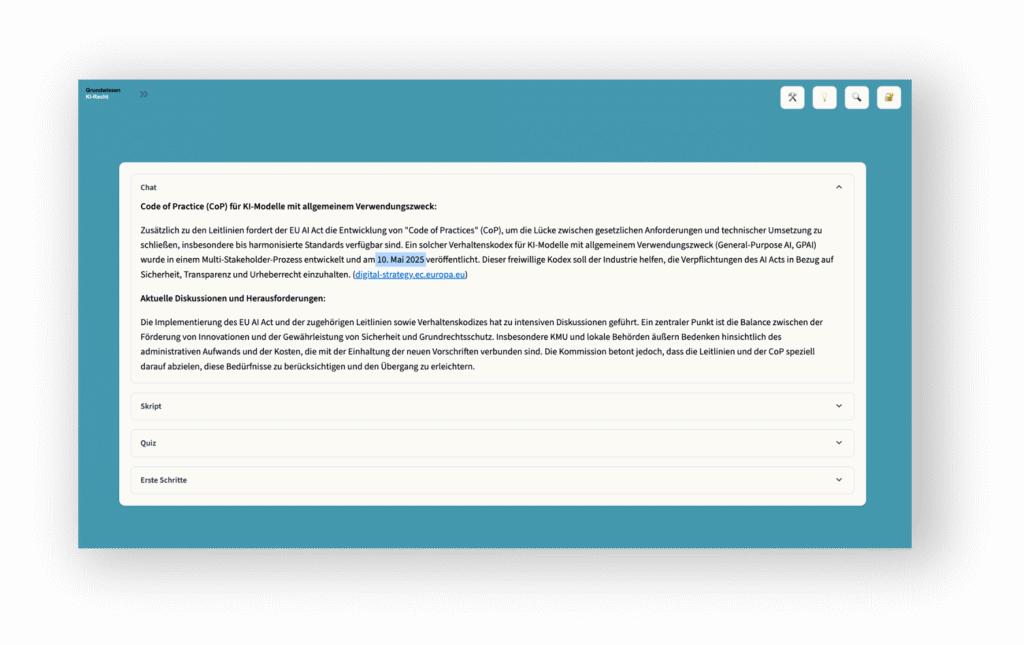
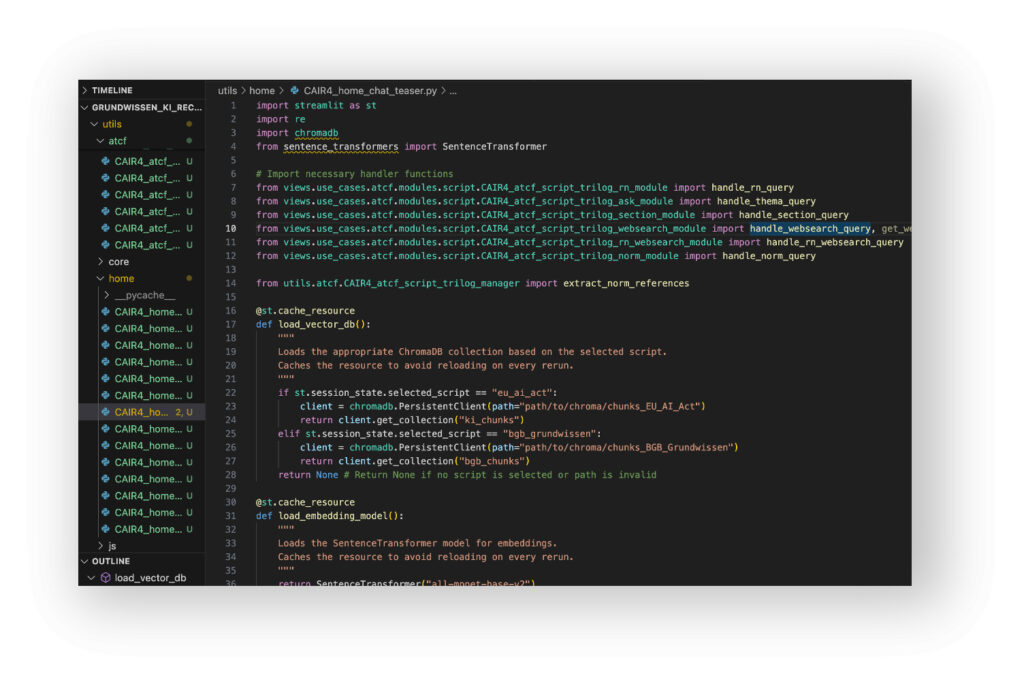
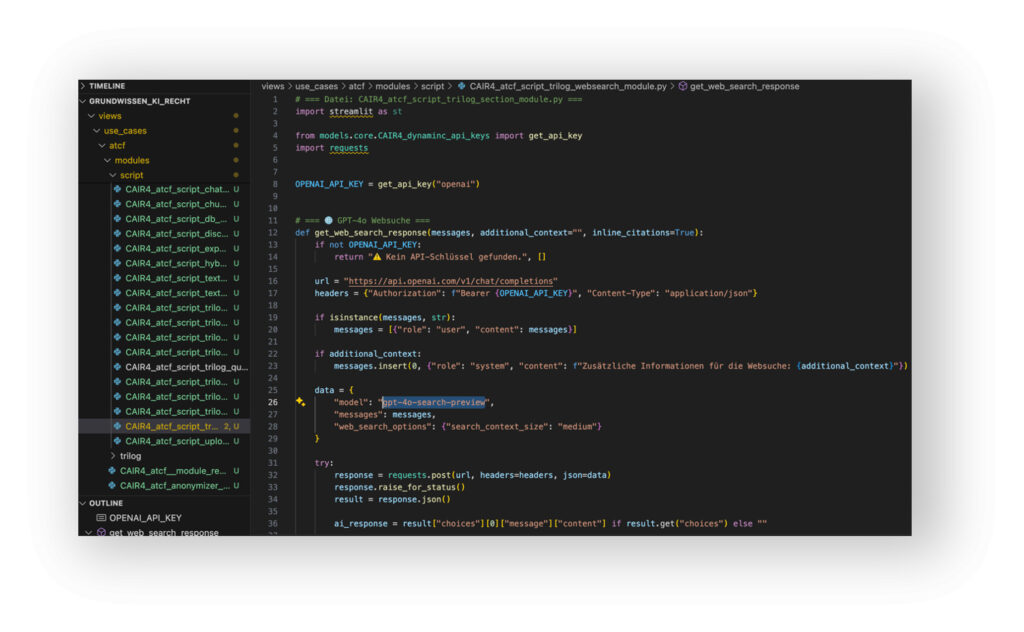
Das Beispiel verdeutlicht, dass sich rechtliche Aspekte des Skripts (wie die Differenzierung von KI-System und KI-Modell mit allgemeinem Verwendungszweck) oft erst auf Code-Ebene genau einschätzen lassen. Mitunter sind es auch unscheinbar wirkende Parameter, die darüber (mit-)entscheiden, ob und wie weit eine menschliche Aufsicht bei einer juristischen KI-Lösung faktische Wirkung entfaltet oder nicht. Für die Erfüllung von Rechenschaftspflichten ein nicht zu unterschätzender Aspekt.
Rechtliche Validierung von KI mit KI
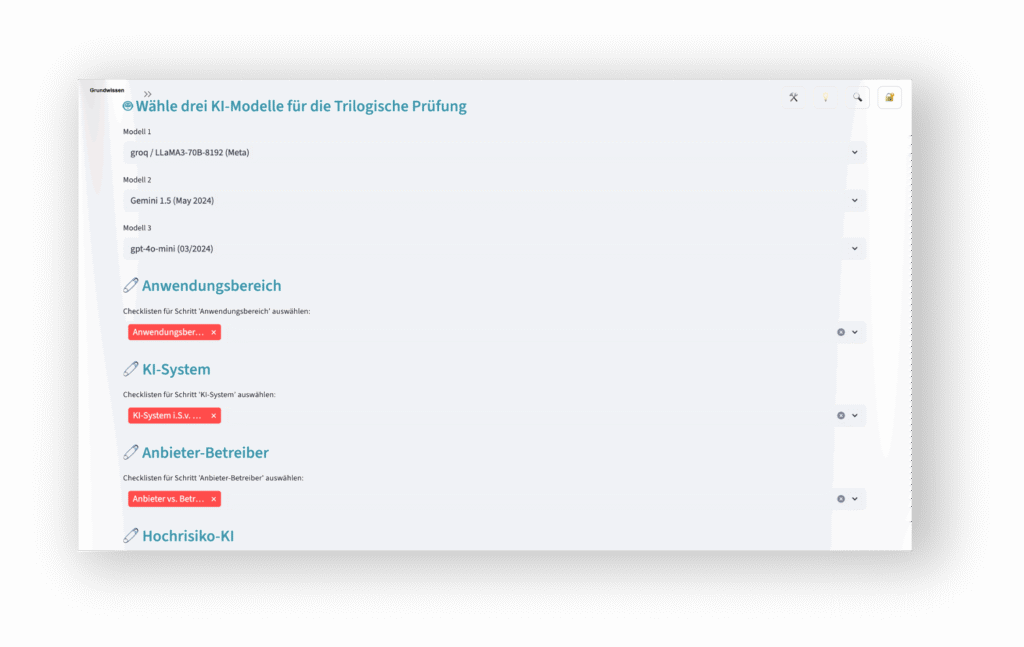
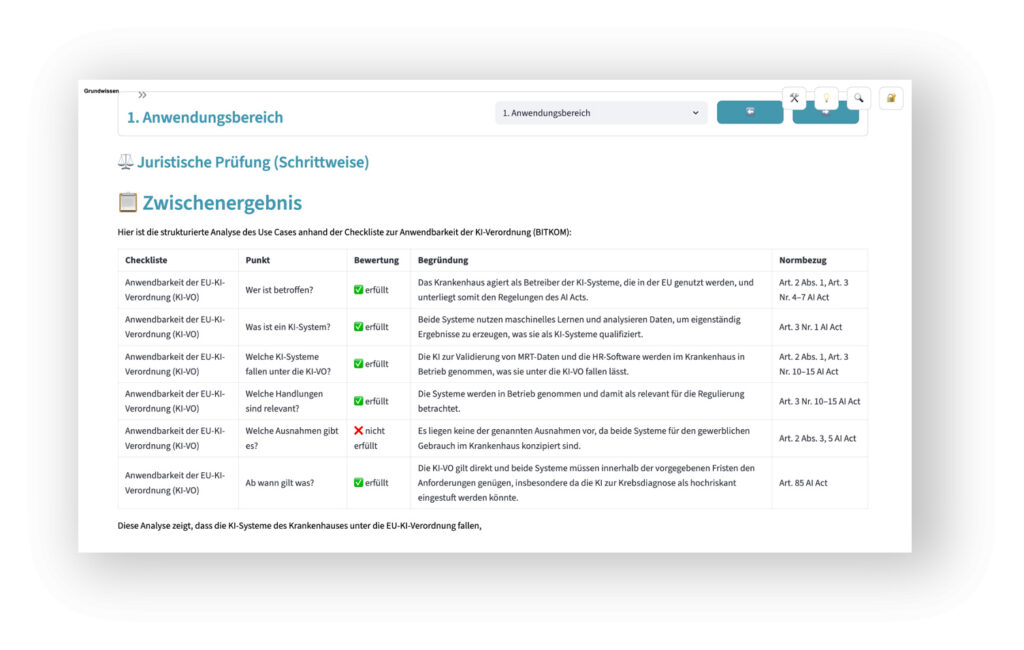
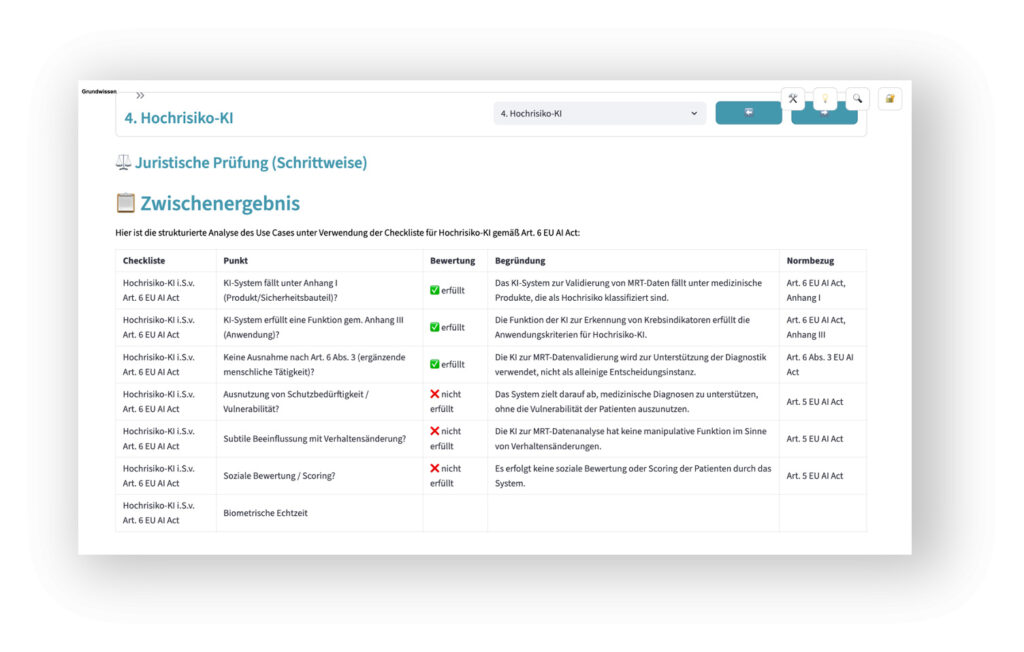
Zunehmend wichtig ist die Frage, ob und wie weit KI-Systeme verläßlich in der Lage sind, komplexe regulatorische Sachverhalte zu bewerten. Nicht zuletzt solche, in denen es um die Frage geht, welche Pflichten der KI-Verordnung im Detail zu beachten sind. Auch hier hilft das Legal-AI-Lab weiter: Unter Berücksichtigung der rechtlichen Skript-Inhalte, verschiedener Gesetze und anerkannter Checklisten zum EU AI Act können unterschiedlichste Use Cases analysiert und bewertet werden.
Ein anschauliches Beispiel ist die automatisierte Beurteilung der Risiko-Klasse von KI-Systemen auf Basis der textlichen Beschreibung:
- von Funktion,
- Nutzern,
- Branche und
- Kontext.
Dabei ist die Frage, wie die Entscheidungsfindung im Sinne einer im Detail nachvollziehbaren Explainable AI (XAI) erfolgt, von hoher Bedeutung. Gleiches gilt für die parallele Prüfung ein und des gleichen Sachverhalts durch mehrere unterschiedlich spezialisierte GPAI-Modelle (u.a. im Wege des Multithreading oder einer trilogischen Prüfung mit wechselseitigen „Checks & Balances“ von KI-Komponenten).
KI-Recht anschaulich erleben
Zusammenfassend läßt sich sagen, dass es das Legal-AI-Lab ermöglicht, eine Vielzahl von oft abstrakten rechtlich relevanten Details rund um KI zu erleben! Das gilt sowohl im Hinblick auf die KI-Verordnung und die sich daraus ergebenden Pflichten als auch die Beachtung von allgemeinen Sorgfaltspflichten, die für alle KI-Systeme gelten können – egal welcher Risiko-Klasse des EU AI Acts sie angehören.
Insgesamt helfen schon jetzt über 100 relevante Use Cases dabei:
- Die im Skript „Grundwissen KI-Recht“ beschriebenen rechtlichen Herausforderungen im Rahmen von Trainings besser zu veranschaulichen, zu verstehen und damit auch praxisgerecht zu lösen.
- Individuelle rechtlich-technische Herausforderungen in Behörden, Unternehmen und Organisationen aller Art zu evaluieren und zu lösen.
- Chancen und Risiken von KI unter Berücksichtigung einer Vielzahl von Use Case bezogenen Faktoren und Szenarien kurz-, mittel- und langfristig zu balancieren.