
Ein US-Richter* hat Thesen zur Nutzung von AI basiertem LegalTech für gerichtliche Zwecke veröffentlicht. Einige davon wurden bereits vor einiger Zeit im Legal AI-Lab erprobt. Eine erfahrungsbasierte Einschätzung.
Worum geht es?
Der US-Richter Jugde Scott Schlegel widmet sich in seinem neuen Blog der Nutzung von LegalTech für gerichtliche Entscheidungen. Interessanter Weise greift er dabei einen Aspekt auf, der bereits im Legal AI-Lab vertiefend verprobt wurde: Das Prinzip der „Checks & Balances“ von mehreren KI-Modellen, die bei juristischen Entscheidungen einander ergänzen bzw. unterschiedliche Aufgaben erfüllen. Doch ist das wirklich die Lösung? Der Weg klingt vielversprechend, ist aber noch steinig!
An dieser Stelle einen Dank an Paul Meyrat, der in seinem Newsletter auf den Artikel von Scott Schlegel hingewiesen hat.

Was schreibt Judge Scott Schlegel?
Auf seinem neuen Blog hat Jugde Scott Schlegel ein PDF mit einem Frameframework veröffentlicht. Es enthält 10 Phasen/Punkte für einen Einsatz von KI im rechtlichen Kontext.
| 10 Punkte von Scott Schlegel | Ziel / Tätigkeit |
|---|---|
| 1. Initiale menschliche Überprüfung | Die Akten lesen, Rechtsfragen und Tatsachenverhältnisse selbst erfassen, entscheiden, ob KI-Einsatz sinnvoll ist. |
| 2. Neutraler AI-Bench-Memo-Prompt (ohne Schlussfolgerungen) | Die KI wird beauftragt, eine sachliche Zusammenfassung von Fakten, Anträgen und Abläufen zu erstellen — ohne Bewertung oder eigene Schlussfolgerungen zu liefern. |
| 3. KI-Ausrichtungstest | Die KI durch gezielte Fragen prüfen: z. B. stärkstes Argument für bzw. gegen eine Position, welche Tatsachen umstritten sind etc. |
| 4. Fehlersuche & Dokumentation | Systematische Beobachtung und Dokumentation, wo die KI Schwächen zeigt (z. B. falsche Interpretation, fehlende Präzision). |
| 5. Erste Entwurfsphase | Auf Basis der gewählten Position lässt man die KI einen ersten Entwurf generieren, der dann redigiert wird. |
| 6. Iteration & Tonangleichung | Der Entwurf wird hinsichtlich Stil, Tonfall und sprachlicher Präzision angepasst, idealerweise anhand früherer richterlicher Texte. |
| 7. Finaler KI-Review & Bereinigung | Die KI leistet einen letzten Durchgang, weist auf mögliche Ungenauigkeiten hin, bevor der Mensch finale Anpassungen vornimmt. |
| 8. Zitierprüfung & Dokumentenabgleich | Menschliche Überprüfung aller Zitate, Kontrolle, dass keine unzulässigen Verweise oder Fehler enthalten sind. |
| 9. Nachentscheidungs-Reflexion | Evaluation des KI-Einsatzes: Effizienz, Fehlerhäufigkeit, Verbesserungsmöglichkeiten etc. |
| 10. Pflege eines Prompt-Archivs | Sammlung bewährter Prompts (Eingabeaufforderungen) zur Wiederverwendung und Weiterentwicklung im Lauf der Zeit. |
Judge Schlegel spricht auch die Idee an, mehrere KI-Modelle parallel einzusetzen („multi-model approach“) und ihre Ergebnisse gegeneinander abzugleichen.
- Ziel sei es, gegenseitige Kontrolle und Fehlerreduktion zu erreichen: wenn zwei oder mehr Modelle zu denselben Ergebnissen kommen, stärkt das die Zuverlässigkeit; divergierende Antworten weisen auf Schwachstellen hin.
- Er beschreibt das als „adversarial testing“ bzw. Cross-Checking, also ein methodisches Hinterfragen, bei dem die KI-Systeme sich quasi gegenseitig überprüfen.
- Damit wird vermieden, dass sich ein Richter unkritisch auf das Ergebnis eines einzigen Modells verlässt, das womöglich Fehler oder „Halluzinationen“ enthält.
Ideen wie die Glühbirne wurden bekanntlich fast parallel an unterschiedlichen Orten gleichzeitig erfunden. Ähnlich auch hier: Die Idee der „multi-Model-Strategy“ von Judge Scott Schlegel wurde im Legal AI-Lab schon vor Monaten operativ umgesetzt und verprobt: Speziell im juristischen Kontext. Die Idee ist gut, aber ihre Umsetzung ist ebenso wie die effiziente Nutzung gar nicht so einfach.
Wozu Check & Balances bei KI?
Das nachfolgende Bild zeigt die Umsetzung eines vergleichbaren Konzepts wie es von Judge Schlegel skizziert wird. Im Kern geht es darum, dass man als Jurist nicht der Willkür oder den (rechtlichen) Halluzinationen eines einzelnen KI-Modells ausgesetzt ist. Mehrere KI-Modelle könnten sich wechselseitig kontrollieren, bevor eine „Joined Decision“ erfolgt.
Abbildung: Trilog des Legal Analyzer im Legal AI-Lab mit der Auswahl mehrerer sich gegenseitig kontrollierender KI-Modelle (Stand April 2025)
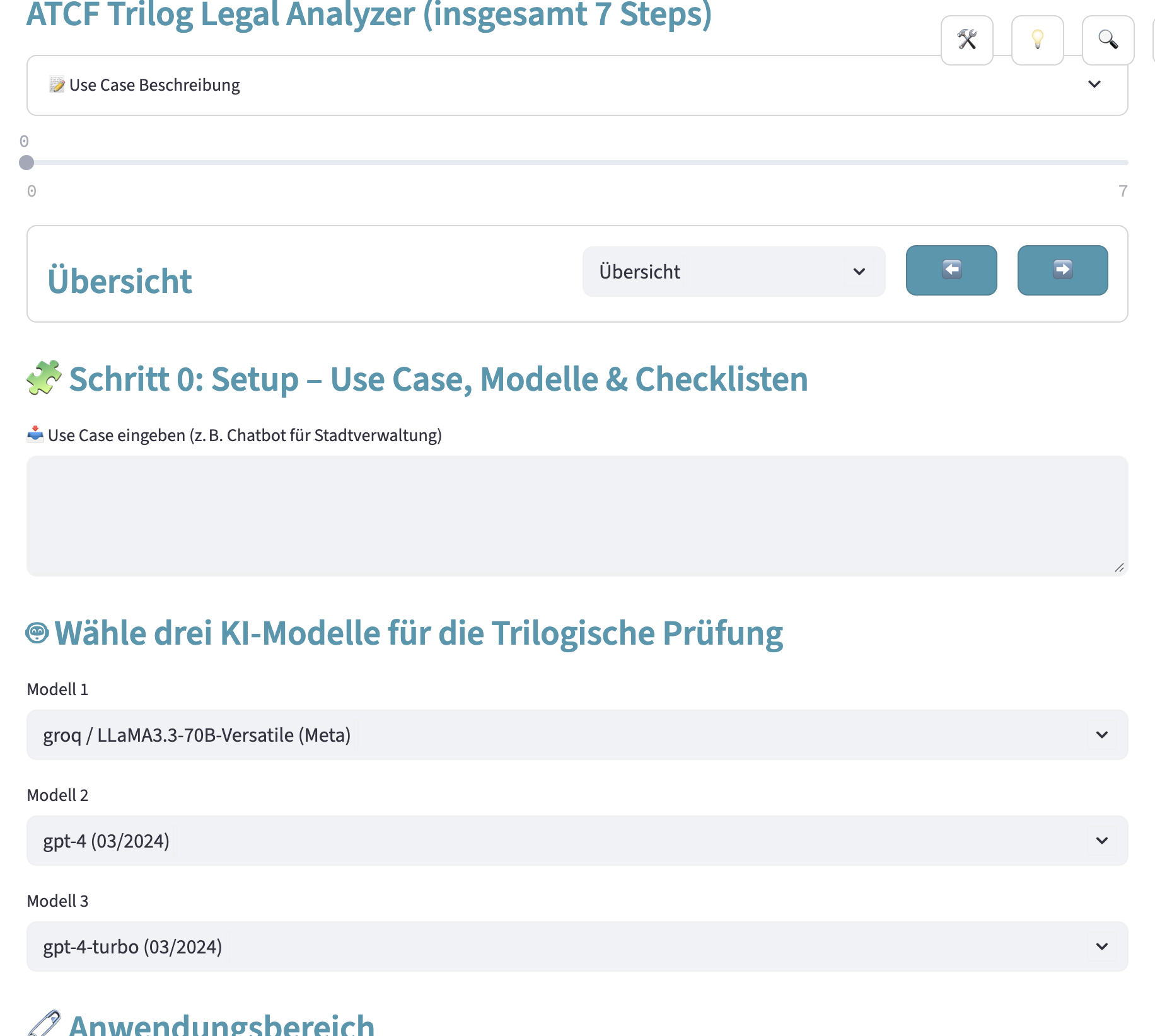
Die Idee dahinter hat etwas mit der (Un-)Fähigkeit von KI-Modellen zu tun:
- KI-Modelle sind oft „betriebsblind“. Sie erkennen im Fall von Halluzinationen oft nicht ihre eigenen Fehler.
- Sie sind aber interessanter Weise umso mehr in der Lage, die Fehler anderer KI-Modelle zu erkennen.
- Die Kontrolle juristischer Wertungen eines KI-Modells durch ein anderes KI-Modell ist daher grds. eine spannende Technik.
- Vor allem dann, wenn man KI-Modelle unterschiedlicher Art miteinander interagieren läßt, wie Reasoning-Modelle, Mini-Modelle oder Multi-Expert-Modelle, die jeweils andere Stärken und Schwächen haben.
- Diese können sowohl im Wege des „Thread Pooling“ parallel arbeitsteilig, aber auch sequenziell nacheinander im Wege einzelner Prozessschritte eingesetzt werden.
Was besagt die (bisherige) Erfahrung?
Wie gesagt: Im Legal AI-Lab wurde dieser Ansatz in Kombination von Threadpooling und sequenzieller Step-by-Step-Prüfung bereits mehrfach mit verschiedenen KI-Modellen und Prozesschritten durchgespielt. Der Ansatz ist grundsätzlich vielversprechend. Der Erfolg ist aber – leider – bislang von unglaublich vielen Detailfaktoren abhängig, denn es kommt u.a. darauf an:
- Welche konkreten KI-Modelle man im Trilog einsetzt.
- Welche Parameter bei diesen Modellen wie konfiguriert wurden.
- Welche Chunk-, Token- und Zeitvorgaben wirklich bessere Ergebnisse liefern.
Um ein Beispiel zu nennen: In den Tests des Legal AI Labs haben die KI-Modelle von Deepseek, Alibaba und Google selbst in älteren Versionen besser perfomiert als das neueste Modell von OpenAI (gpt 5): Letzteres konnte zwar systematisch überzeugen, verirrte sich aber oft bei der Nennung von konkreten Normen. KI-Modelle wie llama, Claude oder Mistral hatten bei rechtlichen Testaufgaben ebenfalls z.T. erstaunliche Halluzinationen.
Selbst wenn die Ergebnisse der im Legal AI-Lab bereits durchgeführten Untersuchungen nur vorläufig sind: Die Idee des Trilogs – so wie sie auch von Jugde Scott Schlegel skizziert wurde – ist grds. gut. Aber es benötigt eine nicht unerhebliche Anzahl von ergänzenden Tools, damit die Ergebnisse auch wirklich zuverlässig sind u.a.:
- Enge Anbindung von einzelnen KI-Modellen an explizite Gesetzetexte, die im konkreten Fall tatsächlich einschlägig sind.
- Nutzung anerkannter juristischer Prüfschemata durch bestimmte KI-Modelle. Die jeweiligen Schemata müssen im konkreten Fall einschlägig sein.
- Diverse Vorab-Tests im Hinblick auf die Konfiguration aller verwendeten KI-Modelle inkl. der Frage, welche Chunk-Größen und Werte wie Top-K oder temperature bei bestimmten semantischen Analysen verwendet wurden.
Die diesbezüglichen Aufwände sind nicht zu unterschätzen, da sie in jedem konkreten Einzelfall geprüft und ggf. nachjustiert werden sollten, z.B. abhängig davon, um welchen Rechtsbereich es geht oder welche Art von Dokumenten analysiert werden sollen.
Es ist dieser z.T. erhebliche Konfigurations- und Validierungsaufwand, der die spannende Idee des KI-Trilogs von der Umsetzung einer tragfähigen juristischen Arbeitshilfe unterscheidet.
Fazit
Die Rolle des menschlichen Richters bleibt unverzichtbar. Die von Judge Schlegel skizzierten 10 Phasen zeigen sehr deutlich: Der Mensch – der juristische Experte – ist in diesem Prozess kaum austauschbar.
Der Multi-Model-Ansatz ist ein vielversprechender Ansatz zur Risikominderung. Er schützt Richter vor den Halluzinationen eines einzelnen Modells, indem er ein internes System der gegenseitigen Kontrolle (Checks & Balances) etabliert. Am Ende wird es aber auf den Einzelfall ankommen, ob und wie weit sich (Kontroll-)Aufwand und Ergebnisqualität die Waage halten.
Allgemeine Information zu LegalTech-News.
Inhalte des Beitrags, u.a.:
- LegalTech
- Gerichts-KI
- USA
- Trilog-Verfahren
* Aus Gründen der besseren Lesbarkeit wird im Text die männliche Form verwendet, die weibliche Form ist selbstverständlich immer mit eingeschlossen.